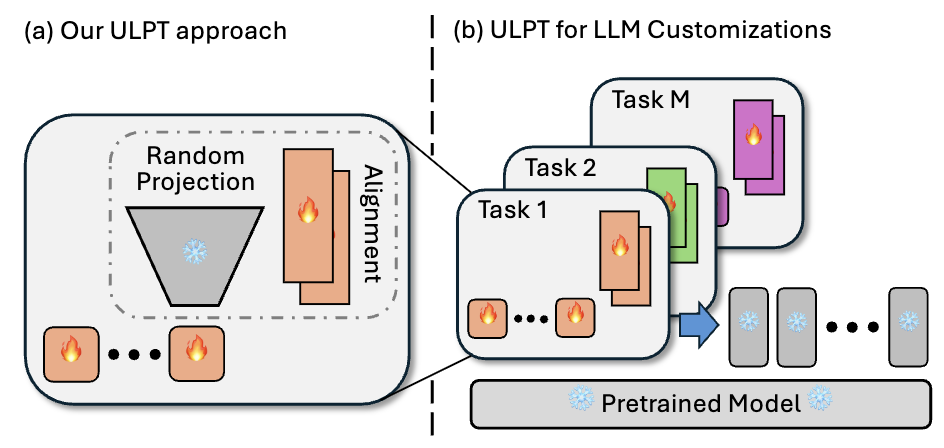
ULPT: tuning a soft prompt in two dimensions
Fine-tuning a modern language model is expensive. So a lot of recent work asks a cheaper question: instead of updating billions of weights, can we just learn a small “nudge” that steers a frozen model toward our task?
Prompt tuning is one of the tidiest answers. Rather than writing a prompt in words, you prepend a handful of learned vectors — “soft” prompt tokens — to the input and train only those. The model stays frozen; the soft prompt carries the task. It works surprisingly well, and you only store a tiny prompt per task instead of a whole model.
But there’s a hidden tax, and that tax is what ULPT (Wu et al., 2026) goes after.
The hidden tax: the model picks your dimension
Here’s the catch with soft prompts. Each prompt vector has to live in the model’s hidden dimension — the width the model uses internally, often several thousand numbers wide. So even a “small” soft prompt of, say, 10 tokens isn’t 10 numbers; it’s 10 × d, where d might be 2048 or 4096.
You didn’t choose that width. The model did. Your parameter budget is dictated by the architecture, not by how much steering your task actually needs — and that puts a floor on how cheap prompt tuning can get.

Vanilla prompt tuning trains the full width; ULPT trains a tiny vector and expands it for free.
The idea: tune small, project up
ULPT’s move is almost cheeky in its simplicity. Optimize the prompt in a tiny space — as few as two dimensions — and use a fixed random matrix to blow it back up to the width the model expects.
Concretely, for each soft-prompt position you learn a tiny vector z (think 2D). A frozen random matrix R up-projects z into the full d-dimensional embedding the model consumes. You only ever train the little z vectors. The random matrix is generated once and never updated — it costs nothing to learn and nothing to store (you can regenerate it from a seed).

Only the little vector is learned; the random projection and the model stay fixed.
Why does a random matrix work?
This is the part that feels like it shouldn’t work, but does. A random projection doesn’t need to be “trained” to be useful — random high-dimensional maps tend to preserve the structure of whatever you feed through them. The fixed matrix acts like a rich, pre-laid set of directions in the model’s embedding space, and the handful of trainable coordinates in z just decide how to mix them.
In other words, the expressive width still comes from the model’s full dimension — you simply don’t have to pay for it in trainable parameters. The learning happens in a two-dimensional knob box; the random matrix turns those knobs into a full-width signal.
Does it actually work?
Yes, and by a comfortable margin on the metric that matters here. ULPT reaches roughly a 98% reduction in trainable parameters compared to vanilla prompt tuning while preserving performance.
And it’s not a one-task fluke. Across more than 20 NLP tasks, ULPT consistently outperforms recent parameter-efficient tuning methods while using significantly fewer parameters. That combination — competitive accuracy at a fraction of the parameter cost — is exactly what you want if you plan to host many task-specific customizations of the same backbone.
Spend your budget on length, not width
There’s a result here I find especially telling. Fix the parameter budget — say you’re allowed a certain number of trainable values, full stop — and ask how best to spend it. You could buy a short prompt of full-width vectors, or a long prompt of low-dimensional ones. ULPT shows the long, low-dimensional prompt wins, and not by a little.

Same budget either way — but spending it on more low-dim positions beats fewer full-width ones.
It’s an intuitive trade once you say it out loud: with the same budget, would you rather have a few very precise steering vectors or many coarser ones? It turns out more positions to steer from matters more than more precision per position. The model benefits from a longer soft prompt it can attend to, and ULPT’s cheap-per-token design is what makes that length affordable in the first place. Width was the expensive luxury; length is where the budget is better spent.
Why I think this matters
If you want to serve a model that behaves differently for hundreds or thousands of customers or tasks, the bottleneck isn’t really inference — it’s storage and management of all those adaptations. ULPT shrinks each adaptation to a few numbers per prompt position, which makes “a model plus a giant library of cheap task tweaks” genuinely practical.
The deeper takeaway I keep coming back to: the dimensionality of what you tune doesn’t have to equal the dimensionality of what the model uses. A fixed random map cleanly decouples the two — and once you see that, a lot of parameter budget turns out to be optional.
The full method, ablations, and per-task numbers are in the paper.
References
2026
- EACL
 Ultra-Low-Dimensional Prompt Tuning via Random ProjectionIn Conference of the European Chapter of the Association for Computational Linguistics , 2026
Ultra-Low-Dimensional Prompt Tuning via Random ProjectionIn Conference of the European Chapter of the Association for Computational Linguistics , 2026
