TokMem: packing a whole procedure into a single token
If you use a language model for anything repetitive, you have probably built up a little collection of prompts. The careful instructions for formatting a meeting summary. The system message that makes the model answer like a patient tutor. The five-paragraph specification that turns it into a halfway-decent SQL generator.
Each of those is a procedure — a reusable recipe for getting the model to behave a certain way. And every single time you want to use one, you have to paste the whole thing back into the context window. The model then re-reads it, token by token, before it does anything useful. The recipe never gets learned; it gets re-explained, over and over.
That re-explaining is the problem TokMem (Wu et al., 2026) sets out to fix.
The cost of explaining yourself every time
Prompting is a wonderfully flexible way to steer a model, but it has two stubborn downsides.
First, it doesn’t scale with reuse. A long procedure costs the same amount of compute on the thousandth query as it did on the first, because the model reprocesses the entire prompt afresh each time. The recipe is stateless.
Second, prompts don’t compose cleanly. If you have twenty procedures and a task needs three of them, you end up concatenating three blocks of instructions and hoping they don’t step on each other. There’s no tidy way to say “use procedure #7 here, then procedure #12.”

Prompting re-feeds the whole recipe each time; TokMem replaces it with one small token.
One token per procedure
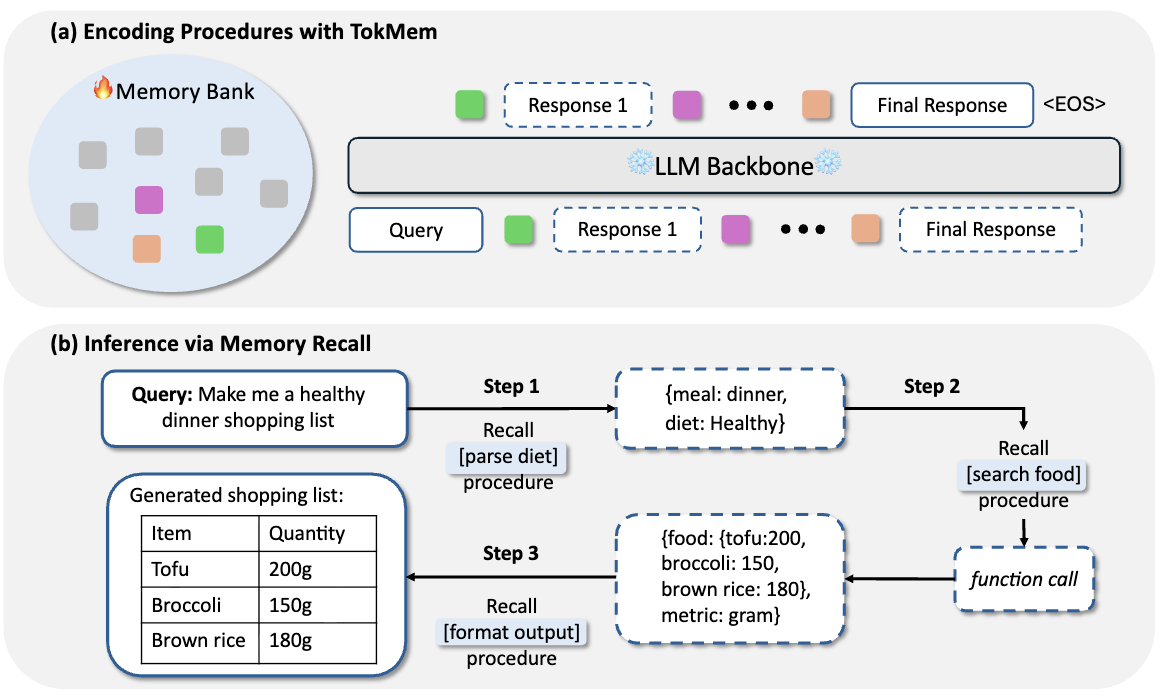
TokMem’s idea is to stop re-explaining and start remembering. It compiles each reusable procedure into a single trainable token — a “memory token” — and stores it away. When you want that behavior, you don’t paste a paragraph; you just reference the token.
The neat part is that this one token plays two roles at once:
- It’s an index — it identifies which procedure you’re invoking, the way a name in a phone book points to a specific entry.
- It’s a control signal — once selected, it actively steers the model’s generation toward that behavior.
So a single unit answers both “which recipe?” and “now cook it.” And because it’s always just one token, the overhead is constant — it doesn’t grow with how long or complicated the original procedure was.

One memory token, two jobs: pick the procedure, then steer the generation.
Keeping the model frozen
Here’s the design choice I find most satisfying. The backbone language model itself never changes. All of the procedural knowledge lives inside these small, dedicated memory tokens, not in the model’s weights.
That separation buys two things that are hard to get otherwise:
- You can keep adding procedures forever. Learning a new memory token doesn’t touch the existing ones, so there’s no catastrophic forgetting — adding skill #500 doesn’t quietly break skill #3.
- No retraining the whole model. Each procedure is a tiny, isolated thing you train on its own, while the expensive backbone stays put.
It turns a monolithic model into something closer to a model plus a growing library of plug-in skills.
Does it actually work?
We tested TokMem in two settings.
The first is atomic recall: can a memory token reliably reproduce one specific procedure? We checked this across roughly a thousand tasks drawn from Super-Natural Instructions — a broad, messy mix of real instructions.
The second is compositional recall: can the model chain several procedures together to solve a multi-step problem, the way you’d compose function calls?
Two comparisons matter. Against retrieval-augmented prompting — the standard “look up the relevant instructions and paste them in” approach — TokMem comes out ahead while shedding the repeated-context cost that prompting pays on every query. And against parameter-efficient fine-tuning, it matches or exceeds the quality using substantially fewer trainable parameters.
In other words, it’s competitive on accuracy and cheaper on both counts that usually trade off against each other.
Why I think this matters
The mental model I keep coming back to: prompts treat a procedure as something you re-explain; TokMem treats it as something you remember. Once a behavior is worth keeping, it deserves a compact, reusable home — not a paragraph you re-type into the context window forever.
If that idea scales, it points toward frozen models backed by ever-growing libraries of single-token skills: modular, cheap to extend, and free of the interference that makes continual learning so painful today.
If you’d like the full details, the experiments, and the math I glossed over here, the paper is on arXiv.
References
2026
- ICLR
 TokMem: One-Token Procedural Memory for Large Language ModelsIn International Conference on Learning Representations , 2026
TokMem: One-Token Procedural Memory for Large Language ModelsIn International Conference on Learning Representations , 2026
